
上一篇我们介绍了机器视觉的评价指标,知道了核心关键指标和指标拆解的意义。那么是不是直接看这些指标就万事大吉了呢?
并不是。计算机视觉并不是一个单一的任务,不是看到一张图,就立即完成了识别,它包括多项任务。当任务彼此叠加的时候,指标也会随着前一个任务准确率的影响,而影响最后的指标。
8 大视觉任务
机器视觉是复杂的,它可以被分为以下 8 大任务。一个 AI 场景的开发不一定会把所有任务都用上,但是一般会涉及几个任务的叠加。
包括:
- 图像分类
- 目标检测
- 语义分割
- 实例分割
- 人体关键点检测
- 场景文字识别
- 目标跟踪
1. 图像分类
图像分类在计算机视觉中是一个非常重要的任务,将一张图像归类到某一类别。想象你在超市,你只是想知道这是不是一个水果,而不需要知道具体是哪种水果。

2. 目标检测
目标检测指的是在图像中定位并识别对象。想象你在一个聚会上寻找你的朋友,你不仅要知道他们在哪里(定位)还要知道他们是谁(识别)。


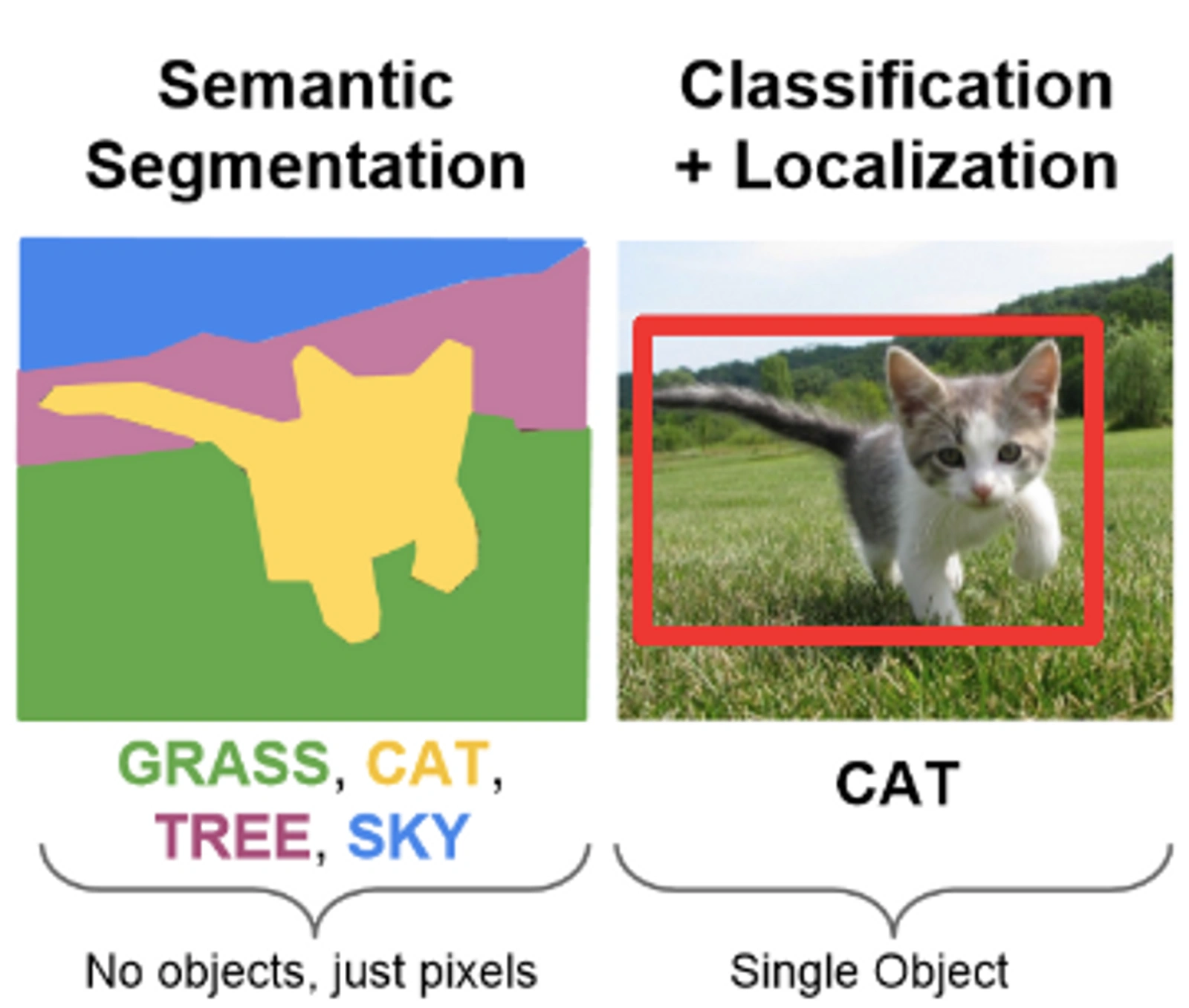
3. 语义分割
将整张图片,每个像素都被分类到某一个类别。想象你正在为一个房间刷墙,每一块墙面都要涂上特定的颜色。语义分割会试图理解图片里面具体的物体和其边界,提供像素的分割。

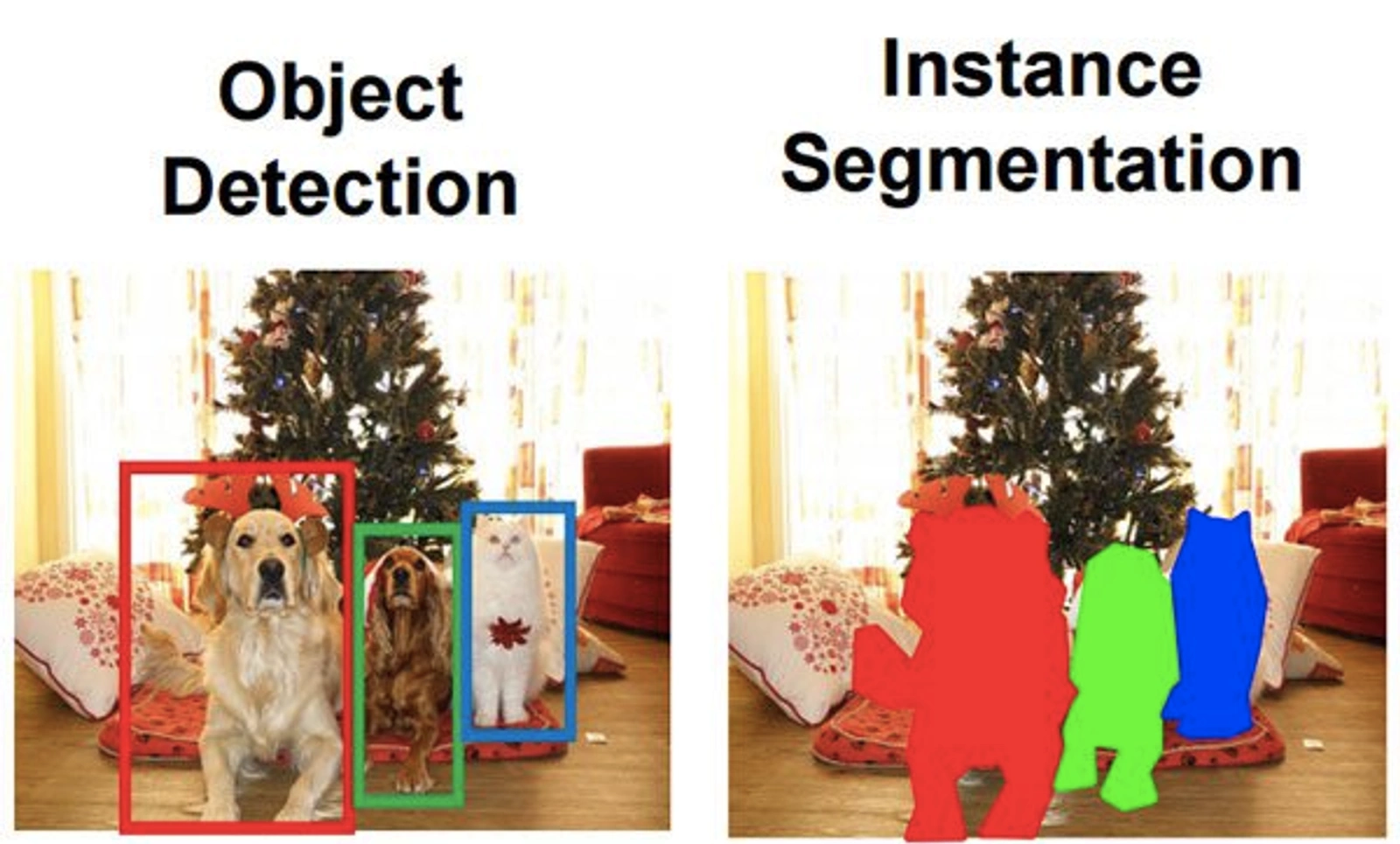
4. 实例分割
与语义分割类似,但实例分割要区分同一类别里不同实例。比如上图中,经过语义分割后,人行聚集在一类像素里面。但是在实例分割中,需要在人行中区分不同的人(person)。

5. 人体关键部位检测
定位人体的关键部位,如肘部、膝盖等,计算机视觉通过检测和追踪人体关键部位从而判断人体的移动和动作。人体关键部位检测对于人体的姿势和预测有着重要的作用。

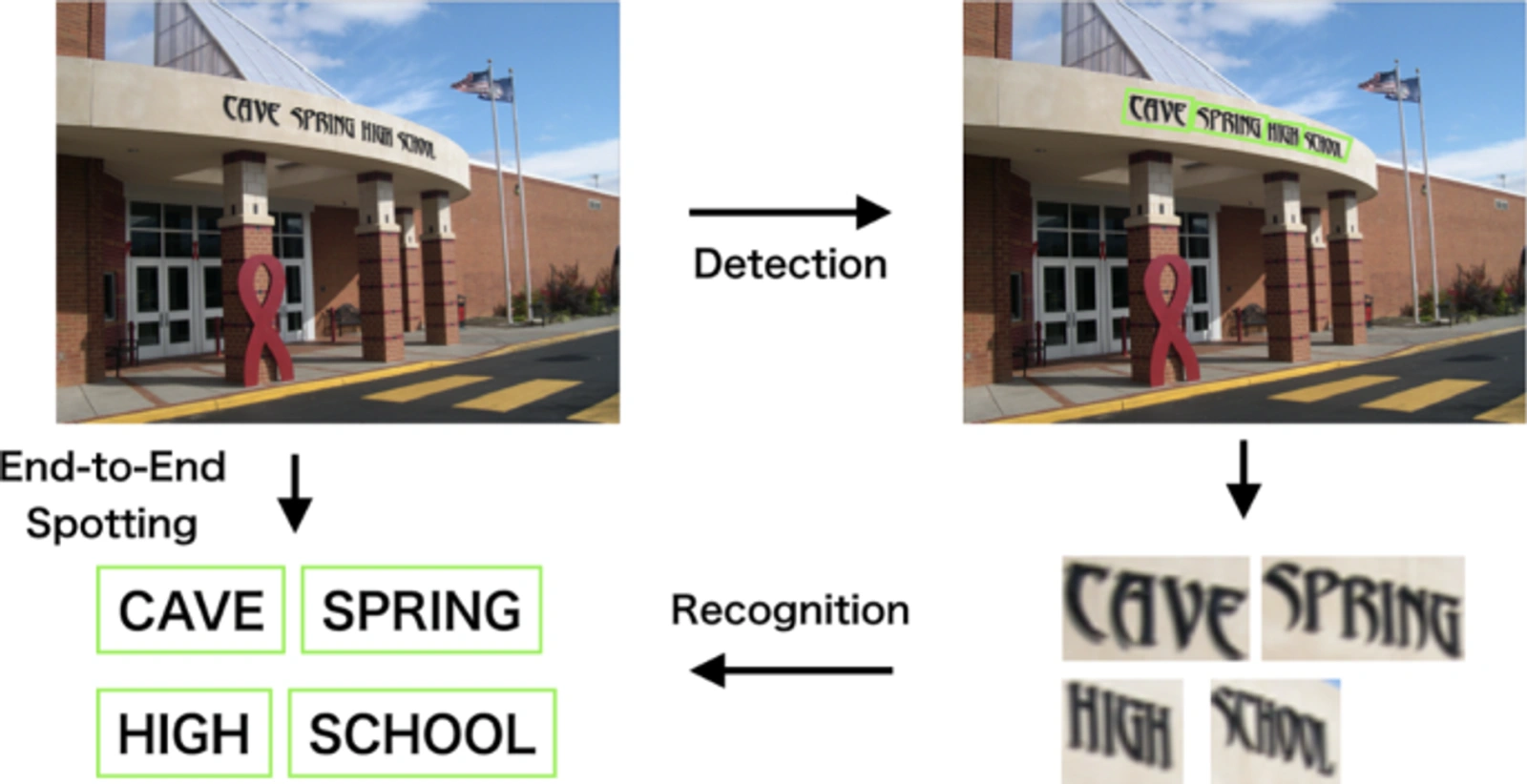
6. 场景文字检测
从图像中的场景里读取文字。想象你在外国街头,试图读懂路标或广告牌上的文字。这些广告牌,在照片里有着复杂多变的背景环境信息,广告牌上字体多样,分布随机。计算机视觉需要将广告牌上的文字转化成文本序列,这个过程叫做场景文字检测。
停车场和收费站的车牌识别是典型的应用场景。当摄像头拍照后,获取车牌信息,判断停车时长,进行收费。
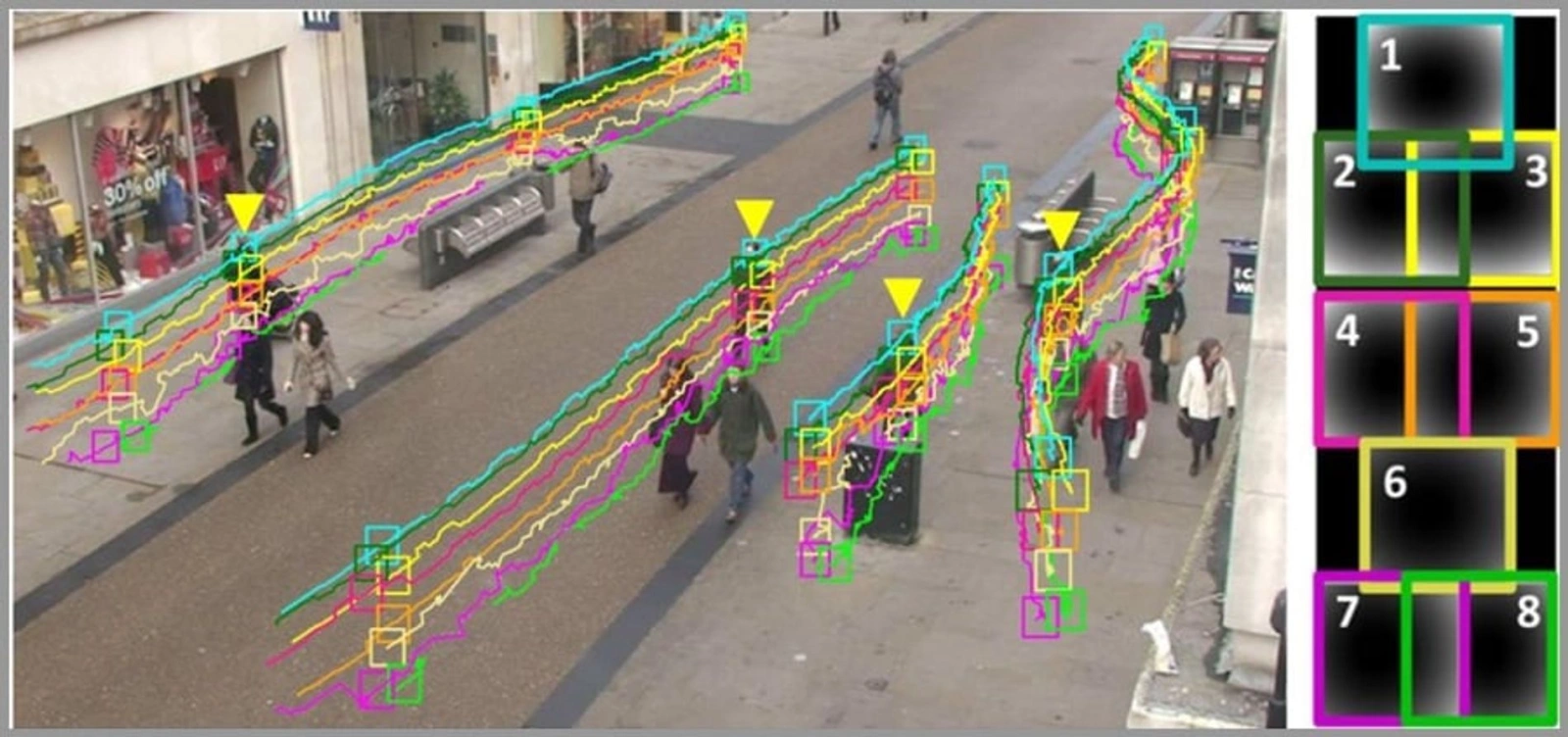
7. 目标跟踪
在视频的特定场景中,持续跟踪一个或多个对象。想象你在公园里放风筝,你的目标是保持风筝在你的视线中并跟随它的运动。这项技术常被用于无人驾驶领域。
8. 叠加的评价系统
当计算机视觉任务彼此叠加的时候,指标也会随着前一个任务准确率的影响,而影响最后的指标。那么如何评价效果呢?
我们举个例子:现在我们要在图片上判断具体是什么蔬菜。 那么计算机视觉需要做两件事情。
- 实例分割,判断产品的检出框
- 判断是什么产品(简称 SKU)

APR 判断
- 首先画检出框的识别准确率
- 在正确的里面区分,蔬菜分类正确的比例
检出框各指标计算公式
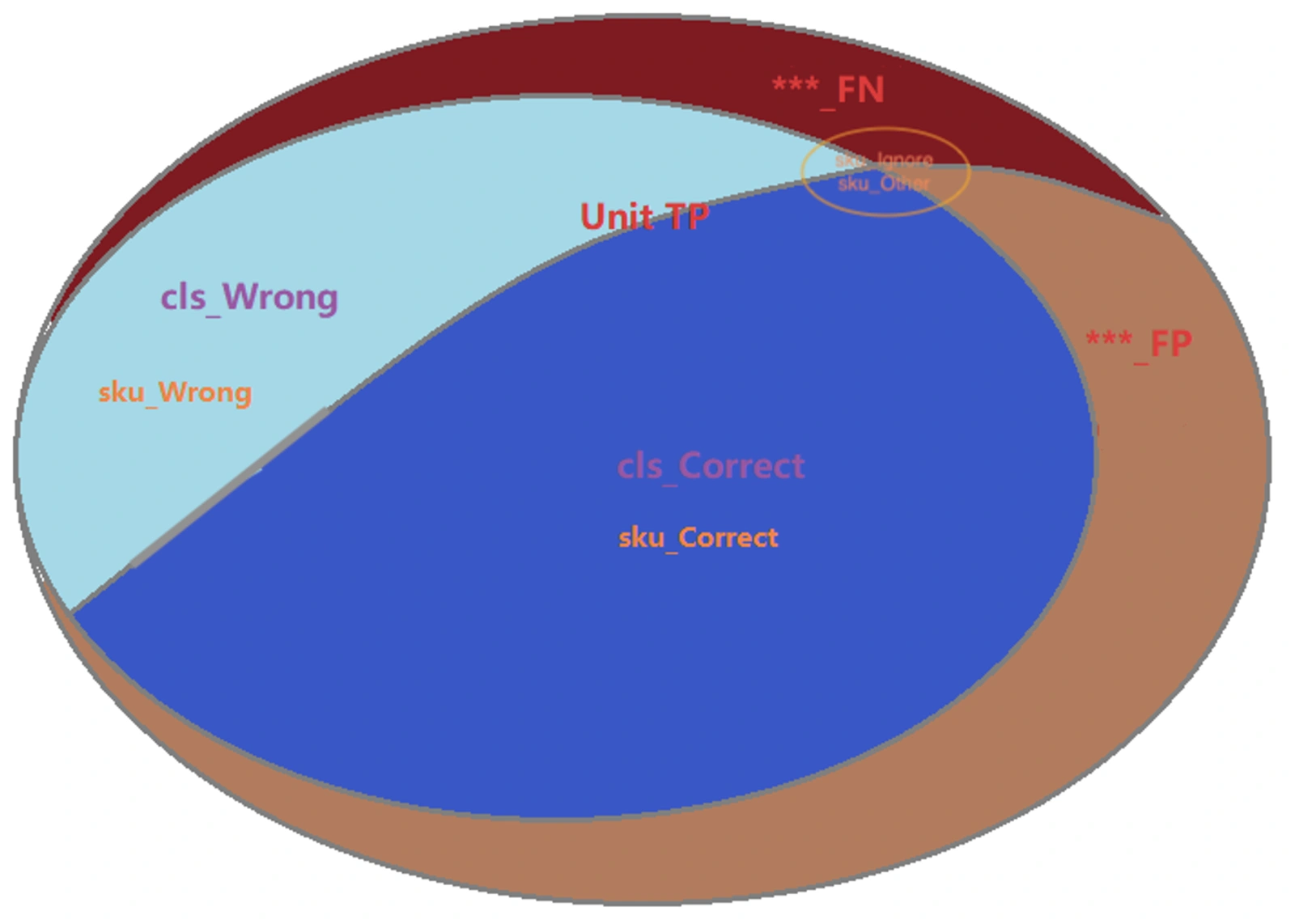
我们简称检出框为 Unit,在上图中:
- Unit TP: 为正确检测出来为检出框的数量
- Unit FN:实际不是检出框,机器也没有检测出检出框的数量
- Unit FP:实际不是检出框,但是机器却检测出来了
- 此场景里面,TN 为 0
那么对于检出框部分:
- detect_recall = unit_TP / (unit_TP + unit_FN)
- detect_precision = unit_TP / (unit_TP + unit_FP)
- detect_accuary = unit_TP / (unit_TP + unit_FP + unit_FN)
分类后各指标计算公式
检出框检测出来后,我们就要对每一个检出框进行分类识别,判断它是西瓜,还是西兰花。我们简称为商品为 SKU, 则分类后的指标判断是在整个上图的 Unit TP 中进行切分的。
还有一些 SKU 我们不认识,因为没有训练过对应的分类模型。这类 SKU 我们把它归为 SKU_ingore, SKU_other。它们可能是 TP, FP, FN 里面任何一个。
在 Unit TP 中,分类正确的,我们叫 sku_correct(图上 cls_correct 和 sku_correct 是一个意思);分类错误的,我们叫 sku_wrong((图上 cls_wrong 和 sku_wrong 是一个意思))
- 单个 sku_cls_accuray = sku_Correct / (sku_Correct + sku_Wrong)
- all_sku_cls_accuray = cls_Correct / (cls_Correct + cls_Wrong)
- e2e_accuray = sku_Correct / (sku_Correct + sku_Wrong + unt_FN + unit_FP)
这里需要注意的是,当我们是整体端到端效果和准确率的时候,其实指的是 e2e_accuracy,e2e 指的是 end to end 的意思,也就是实际整体的正确率是多少。
所以通过公式可以看出,涉及多个计算机视觉任务的评价指标,是嵌套关系,每一个任务的准确度都会影响下一个任务的指标。下一个任务的准确率是在前一个任务正确的分母里进行的 FN, FP 的拆分。
总结
计算机视觉的评价指标有些绕脑子,一旦想不明白的时候,画图可以帮助我们很好的理解。同时记住,T 表示的实际;P 表示的机器的判断。在画图的圆圈里面拆分错误类型。慢慢熟悉之后,就会快很多。