
当我们在谈论机器学习,或者更具体地说机器视觉时,我们常常听到这样一些词汇:准确率、精准率、召回率。对于产品经理来说,理解这些评价指标的意义及其重要性是十分必要的,它是算法迭代的方向。
但是机器学习的指标太多太复杂,很难入门。此外,计算机视觉较为复杂,它涉及多个任务的叠加,每个任务都有算法指标进行评价,产品需要关注总体指标(也叫端到端指标)的同时,还要能够理解多任务叠加的情况下,每个指标的由来。
我们分两篇来专门针对计算机视觉的评价体系。本篇介绍机器视觉的核心评价指标。
机器学习 3 个核心指标
对于了解机器学习的评价指标,其实不用一开始上来就看指标大全。指标大全会让大家迷失在各种形形色色的 KPI 里面。
我们一开始只要关心核心三大指标即可:
- 准确率 — Accuracy
- 精确率(差准率)- Precision
- 召回率(查全率)- Recall
这里汇总指标为准确率 Accuracy,拆分为两个重点,Precision(我们简称为 P)和 Recall(我们简称为 R)
速记方法
三大核心指标,简称为 APR,速记方法为:
- Accuracy:是对全部样本来说,哪些是正确的。
- Precision:是对预测结果为正的样本中,实际正确的个数。我们可以想象成,自己扔了一个骨头,所有跑过来的“狗”中,有多少只真狗。

- Recall:是实际正样本中,有多少正样本被预测了出来。我们可以想象成,扔了一个骨头,狗是不是都回来了。

当基于机器视觉某个场景,算法进行识别后,产品经理都可以针对 APR 进行提问和查看。
指标拆解
既然有了三大核心指标,APR,那为什么算法同学总是喜欢提及 TN, TP, FN, FP 这些概念呢。而这些概念经常弄的人晕头转向。
我们先解释一下为什么需要 TN, TP, FN, FP 的存在。
先讲两个小故事。
1. 该病人有没有得 HIV?

如果每1000人中有1人携带人类免疫缺陷病毒(HIV),再假设有一种检查可以百分之百地诊断出真正携带该病毒的人。最后,假设这个检查有5%的假阳性率。也就是说,这项检查在没有携带HIV的人中,也会错误地检测出有5%的人是病毒携带者。假设我们随便找一个人来进行这项检查,结果呈阳性,表明此人为HIV携带者。假定我们对这个人的个人史或患病史一无所知,那么他真的是HIV携带者的概率是多少呢?
大部分人的回答是95%,即使是经验丰富的医生,而正确的答案是约2%。
我们假设 1000人中只有1人是HIV携带者。那么1000人中只有1人是真正的HIV携带者。如果另外999人(不患病)也进行检查,由于这一检查有5%的假阳性率,他们当中将有约50人(999 乘以0.05)会被错误地检查出携带HIV病毒。因此,在这51个检测结果呈阳性的人中,只有1人(大约2%)是真正的HIV携带者。
简而言之,基础比率就是绝大多数人都没有携带HIV病毒(病毒携带者只占1/1000)。将这个事实与相当高的假阳性率综合起来考虑,就能使人确信,在绝对数量上,大部分检测结果呈阳性的人并不携带HIV病毒。
而这里的 2% 就是 Precision。在机器检测的所有 HIV 阳性中,正确的个数为 1/51。
2. 我的当事人不是凶手

假设你是一个律师,现在法官要审判一起杀人案件,而你的辩护人被指认谋杀。但是案发时,你当事人在蛋糕房里面做蛋糕,并不在案发现场。现在你要为他辩护。
庭上法官拿出 DNA 检测报告表明,案发现场凶器上的 DNA 和你当事人 DNA 完全吻合。所以你的当事人才被指认。
作为律师你说,“等一等,法官你确定 DNA 匹配不是巧合?”
法官说,“当然,DNA 匹配概率是百万分之一。你的当事人是凶手无疑。”
你说,“别急,我们来画一个图。百万分之一的可能性表达的是所有人群里面,错误识别的可能性。但是我们这里应该要看的是,识别出来的结果里面,被误识别的可能性 。
我们假设该城市有 4百万人,那么误判人数是 4 人 。但是实际只有一个凶手 。

所以我当事人被误判的概率是 1/5 = 20%。
- 实际为真,机器为正的,真正凶手就是 TP
- 实际为假,机器为正的,就是虽然检测是凶手,但是属于被误解,就是上面你的当事人的情况,属于 FP
- 实际为真,机器为负,就是机器检测不出真正凶手的情况,此处为 0,用 TN 表示
- 实际为假,机器也为负,就是非凶手,机器也不判断为凶手的情况,就是将近 4百万的城市人口。
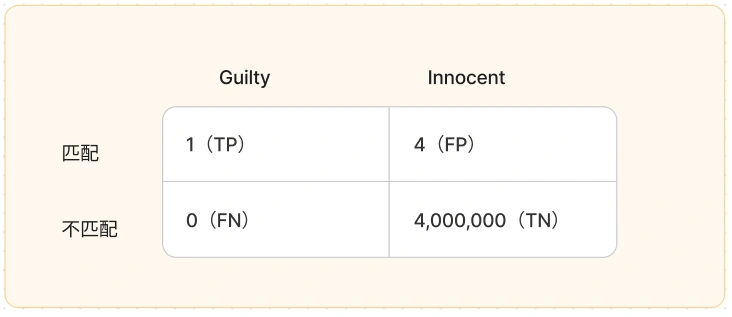
这里的 Precision 为 TP/(TP+FP) = 20%
准确率 Accuracy 为 (TP+TN)/(TP+TN+FP+FN) = 1/近4000000
误识别率 FP/FN = 1/1,000,000
在不同的场景下,我们需要不同的指标来解释和处理。这个故事下,Precision 对你来说是最重要的指标。
总结
所以当我们拆解算法的指标时,可以通过上述矩形框进行拆解。基于不同的场景,选择 APR 等指标。
- 准确率 =(TP+TN)/(TP+TN+FP+FN)
- 精准率 =TP/(TP+FP)
- 召回率=TP/(TP+FN)
实际使用中,不用记 TP,TN,FP,FN 这些组合,只要你画出来 True, False, Positive, Negative 对其进行拆解,计算上面 APR 哪些指标有问题,去查看对应的照片数据集,就会找到问题所在。
概率统计书单推荐
- 统计与概率相关书籍: 《思考,快与慢》
- 《不确 定世界的理性选择》(Rational Choice in an Uncertain World)
- 《思考与 决策》(Thinking and Deciding)
- 《现代世界中的决策与理性》(Decision Making and Rationality in the Modern World)
- 《赤裸裸的统计学》( Naked Statistics: Stripping the Dread from Data
- 《如何不犯错:数学思维的 力量》( How Not to Be Wrong: The Power of Mathematical Thinking )