一、了解 SD 与哩布哩布
1. SD简介
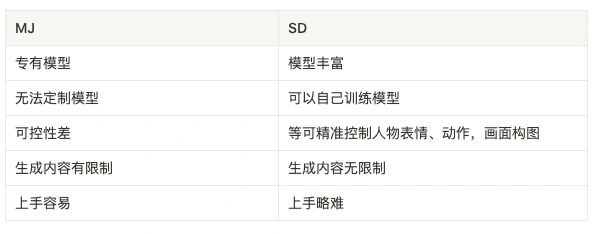
SD全称为 Stable Diffusion,与 Midjourney(MJ)一样,也是一款AI绘画软件,SD 的核心原理是潜在扩散模型(LDM),通过该技术,SD能够将原始图像转化为噪声图像,然后逐渐去除噪声,生成最终的逼真绘画。相比于 Midjourney,它具有更强的可控性,它把一切的控制权都交给你。在许多商业场景中更加实用,操作复杂度也会高一点。但 MJ 与 SD 是目的性不同的工具,MJ是视觉表现工具,SD 是制作取向工具,不同需求者会在不同的阶段使用它们,而且两者并不冲突,在制作上可以相互配合互补。
2. liblib
下面跟大家强烈推荐哩布哩布(https://www.liblib.art/),它原来是一个模型分享和下载的网站,后来有了在线 SD 的功能。其界面设计与原生 SD 基本上一样的,Lib 不仅可以本地部署,并提供了 SD大模型的下载;同时作为一个 SD 生态网站,它可以线上体验 SD 功能,不需要科学上网。
由于本地部署对于电脑硬件要求很高,不仅要求中高端显卡,同时还需要安装和设置软件环境。如果你是AI新人,在没有时间和设备的前提下想要试试AI绘图,照着网上的教程做一些东西,为自己的学习和工作提供更多助力,Lib 线上版会是非常适合你的学习平台和生产工具,目前每天可以免费生成300张,还是很赞的。
本文以下介绍均基于在线版libilibi,适用于新手体验与学习。(对于想要安装本地部署的,以下为网上搜集的安装配置要求,可参考,如果你是Mac本就不用考虑了。)
电脑配置要求 显卡(最重要):N卡 (Nvidia) 显存4GB以上,但是至少8GB用起来才会比较舒服,不然渲染一张512*512的小图就需要几分钟体验感很差。不推荐A卡(AMD) ,最低配置 GTX1060,不到一分钟一张图;建议配置 GTX3060 (AI 绘图入门甜品卡,但小心矿卡)10秒左右一张图;高配 GTX3080GTX4090 ,体验三秒一张图,抽奖抽到爽 内存:尽量16GB 及以上,因为在出图的时候我们除了开SD软件,可能同时会打开各种参考图网站,SU 模型,PS 修图等等,容易卡死,体验贼差。 cpu 处理器:AI 绘图主要用 gpu 计算,不太吃 cpu,与显卡相匹配的处理器就可以。 硬盘储存空间:100GB 以上,软件本体在20-30GB,后期还需要下载很多大的模型,每个模型一般也有2-5GB,还有各种lora模型,所以储存越大越好。 SD基础软件安装:推荐大家直接安装 Stable Diffusion WebUl 资源整合包(网上搜索秋叶的一键安装包)
二、基本界面认识
1. 网站首页
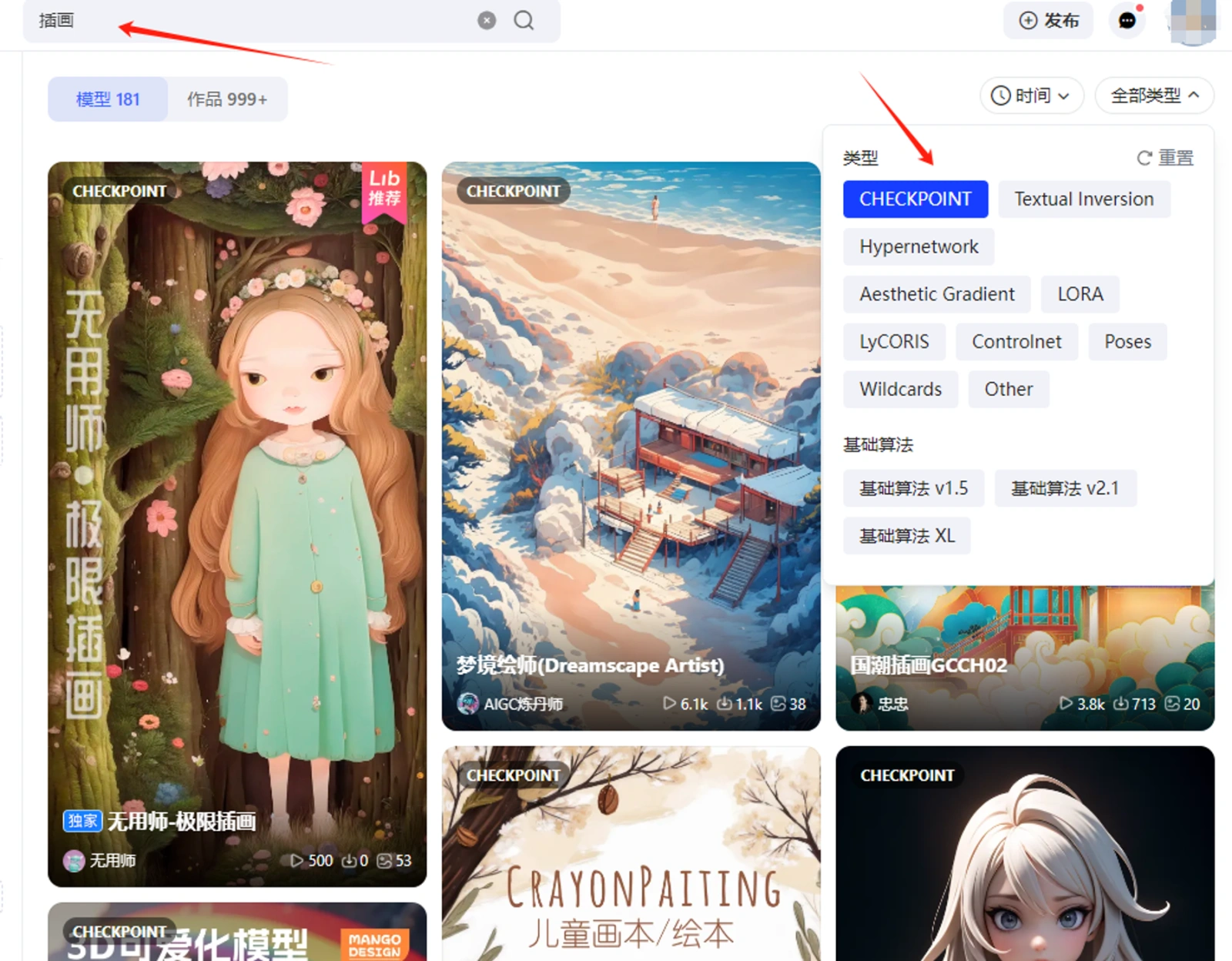
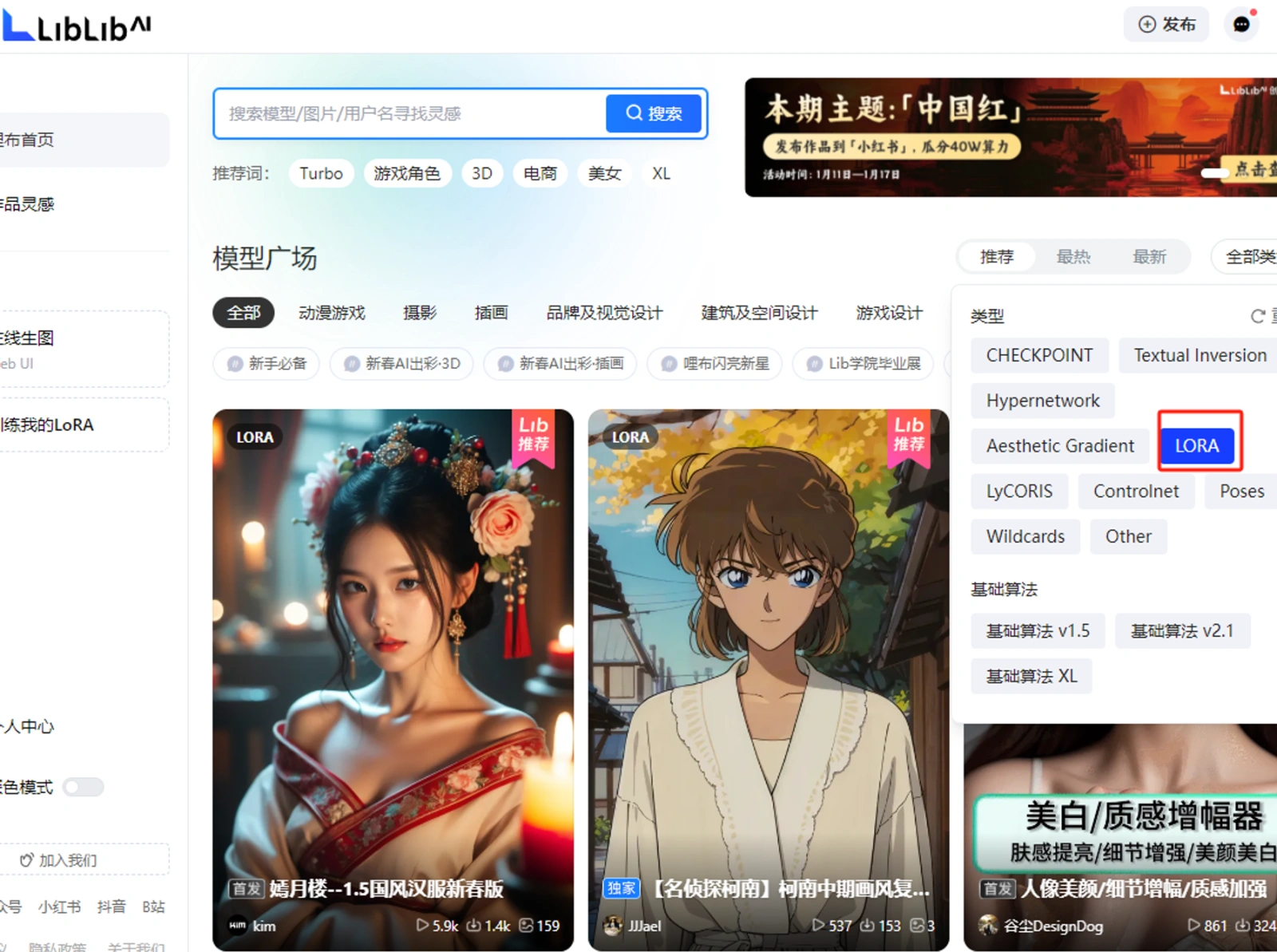
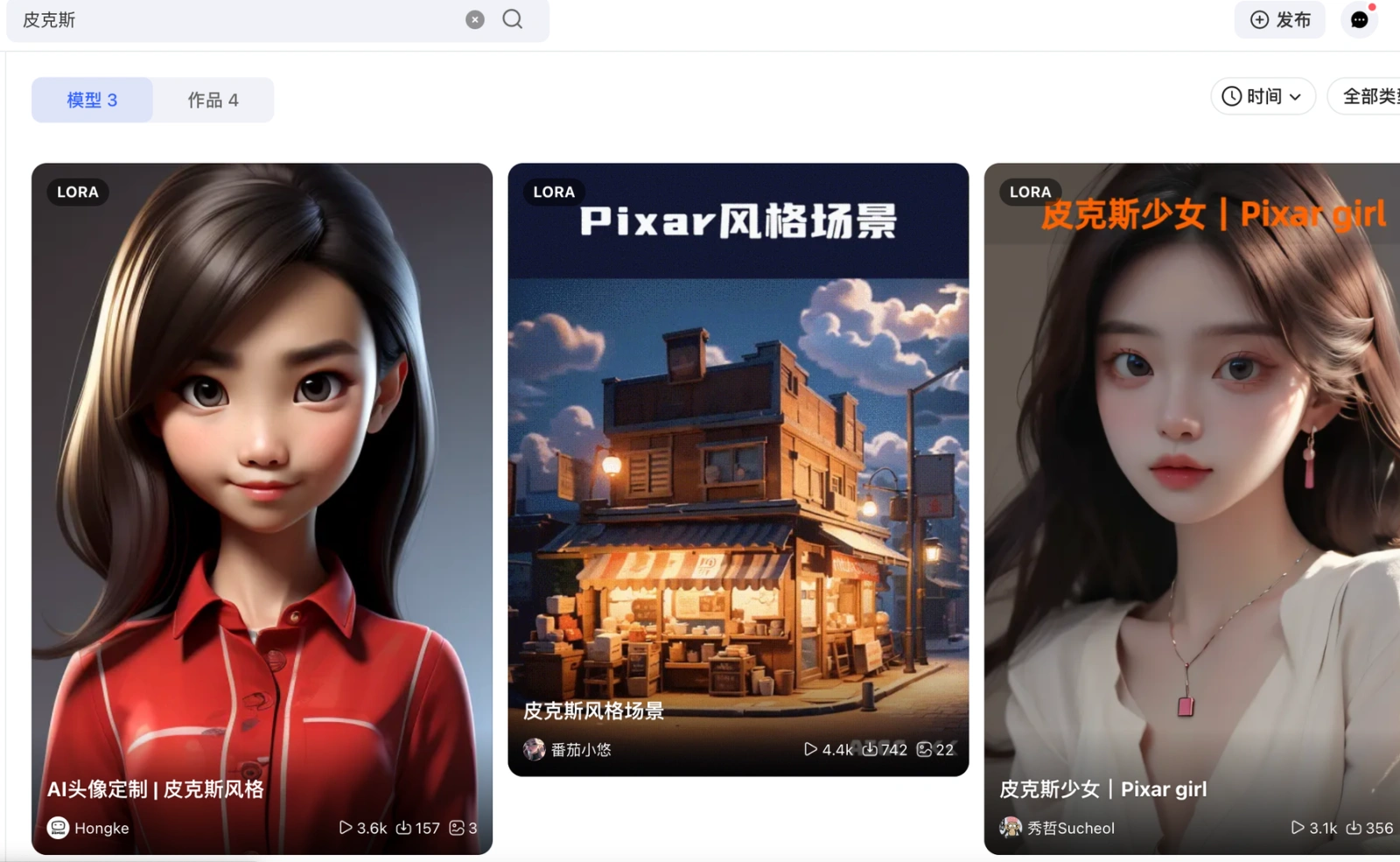
打开网址https://www.liblib.art/后,就到了网站首页,可以看到大幅页面为模型广场,是Lib提供的海量模型库。由于这个特性,我们可以先在Lib上找到众多已经预训练好的模型,一键添加到自己的模型列表中,就可以直接使用。比如,我想要搜索插画类大模型,可以在类型选择 CHECKPOINT,搜索框内写插画,即可找到类似模型。
点右上角注册登录,点左侧创作区域的【在线生图】,即可到做图操作页面。
2. 做图页面
点击在线生图,出现下面到做图操作页面。如下图,主要包括大模型选择框,功能标签栏,提示词填写区,提示词操作区,高级参数设置区,结果生成区,结果处理区(图片生成后出现)。
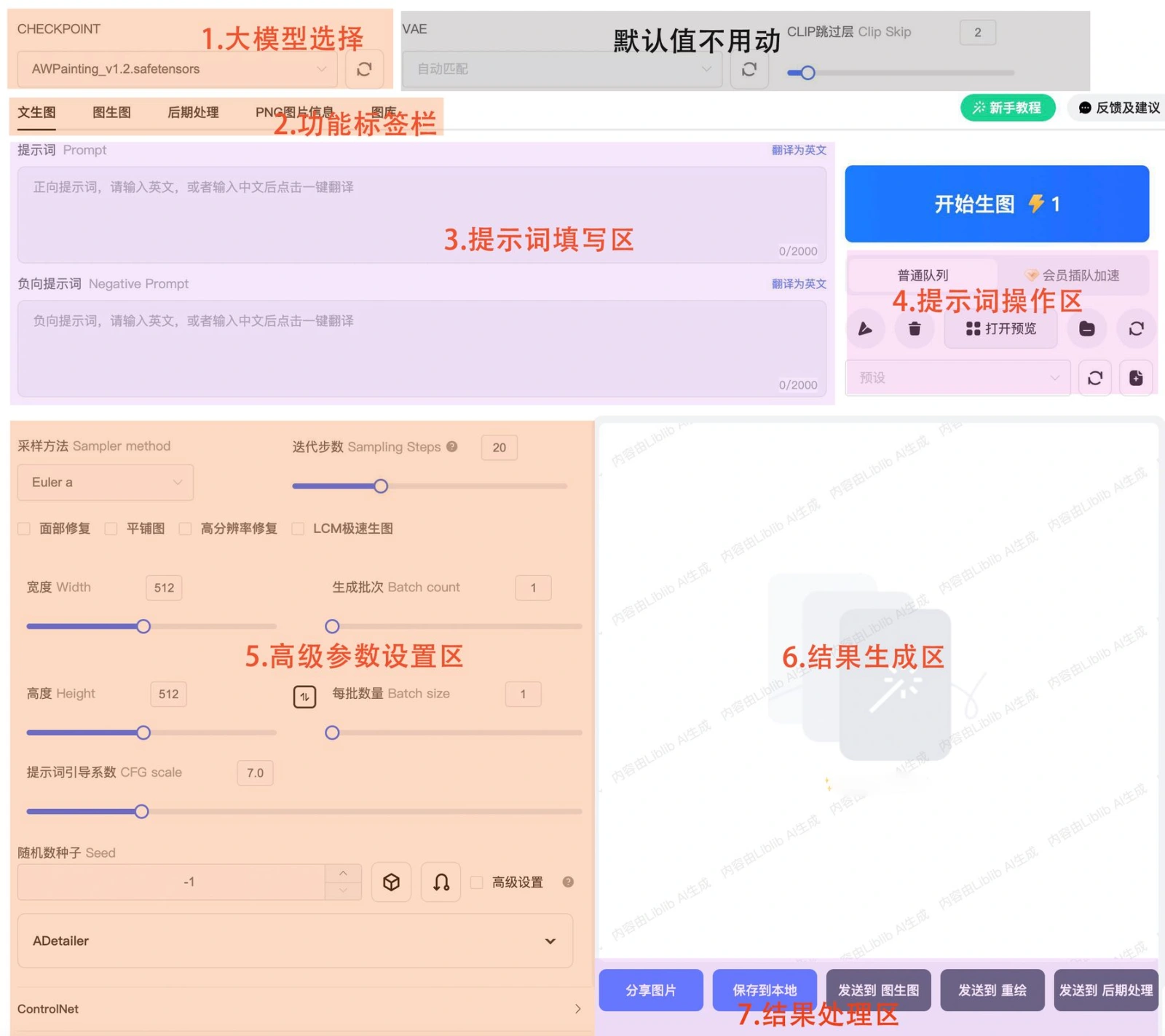
3.关于模型
基本大模型CHECKPOINT(必须要选择)
大模型有3类: 2D二次元模型:动画插画,偏向平面的二次元人物,例如:AWpainting 2.5D模型:偏向3D的动画人物,游戏道具人物,盲盒,玩具等,例如:Rev animated 3D写实类模型:真实影片,真人写真,实物拍摄,例如:Chillout Mix,麦橘写实
前面界面认识部分已经介绍过网站首页就是模型广场,你可以在模型广场去了解和探索自己喜欢的大模型,并进行收藏加入自己的模型库,后面在做图时就可以选择对应大模型出类似风格的图。
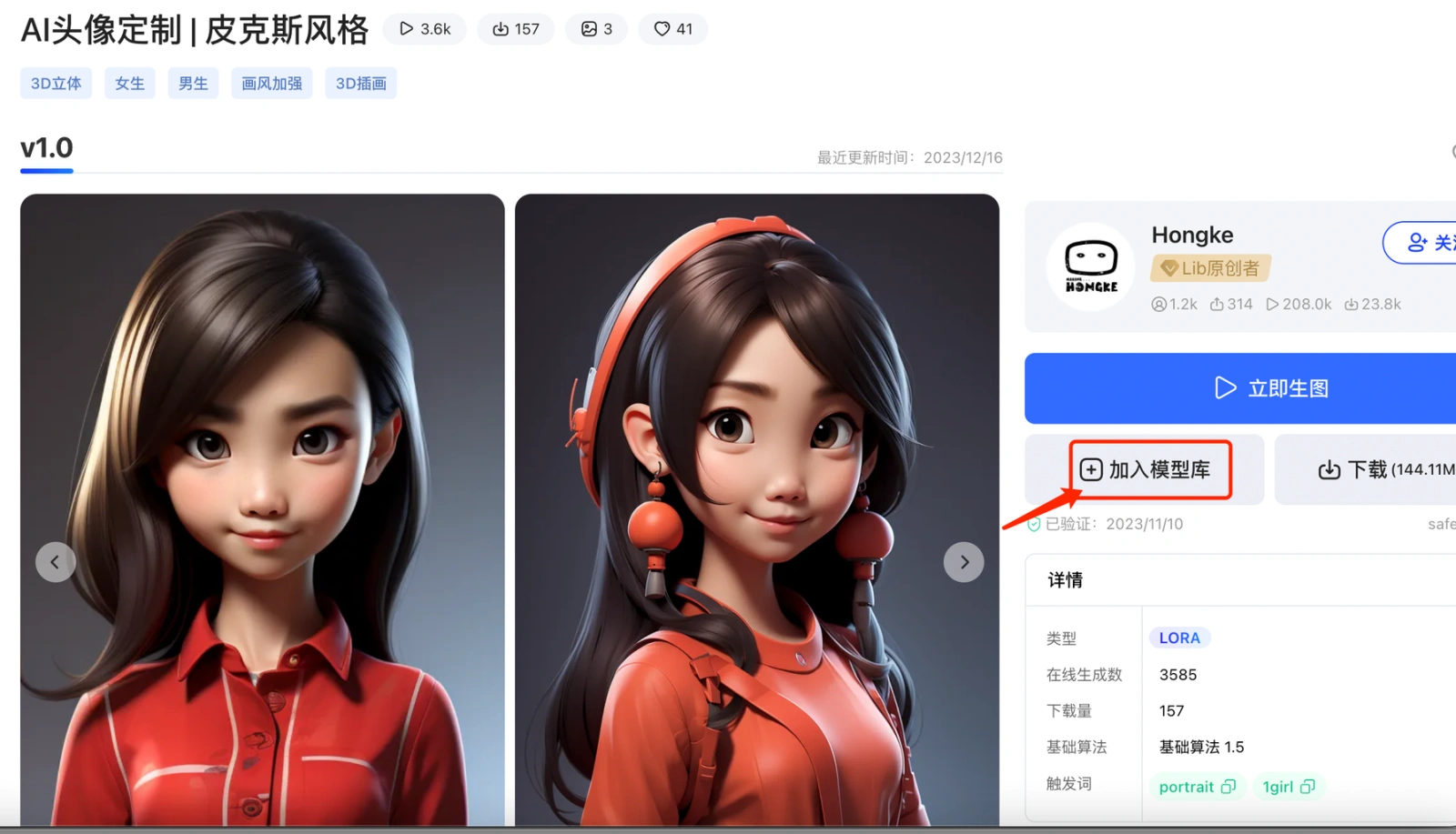
在生图的操作页面,点开左上角的模型选择区域(CHECKPOINT)。(可选默认的模型,也可以自己添加其他各类模型),点击模型后的问号(❓),也可以跳转到模型介绍页面查看其基本介绍信息,如下所示。
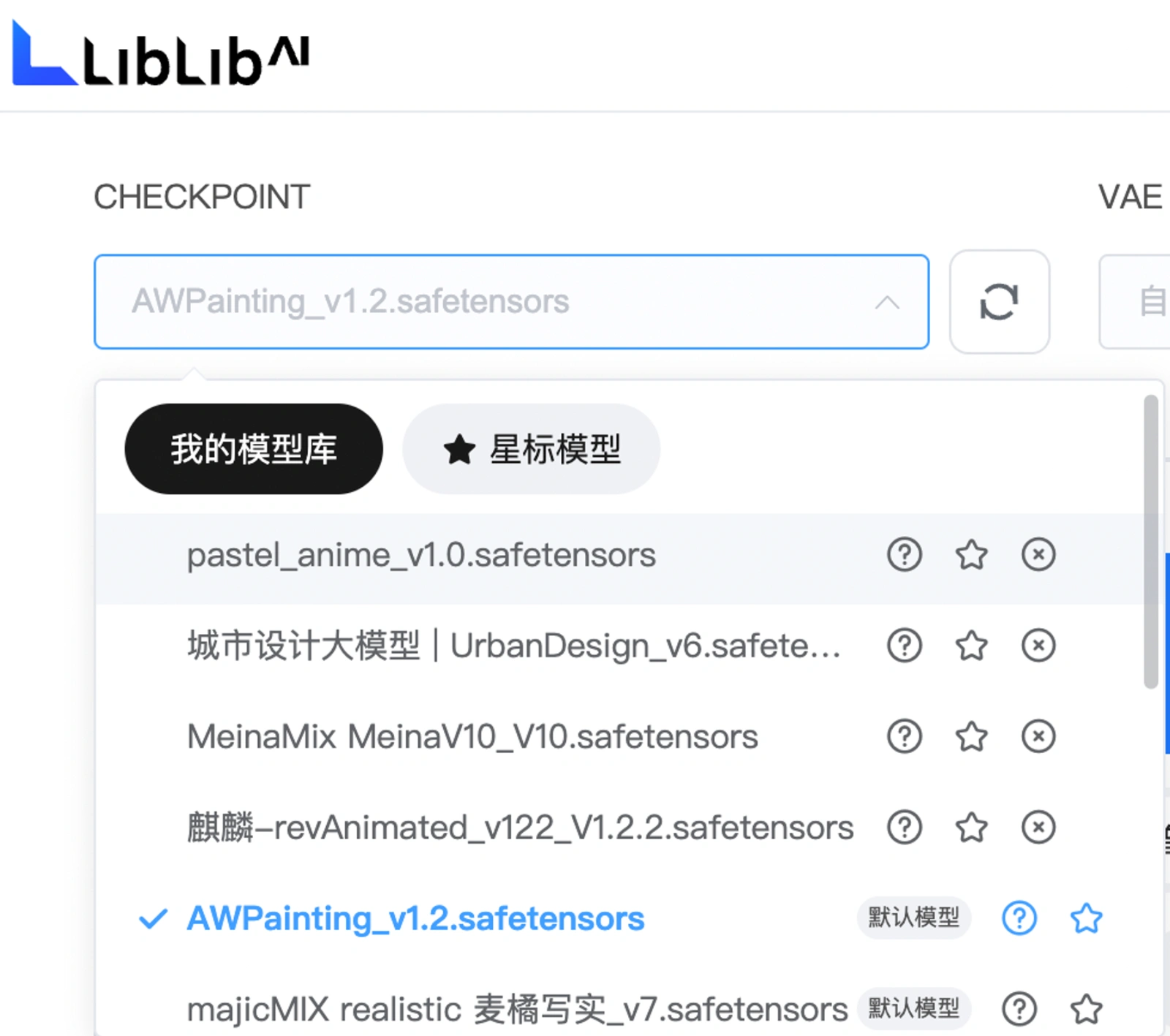
Lora小模型(可选可不选)
Lora为SD的一个插件,可以将其理解为辅助的提示词,让AI有更加细化的风格作为参考,你选择了小模型后,提示词框内会加上对应的触发关键词。
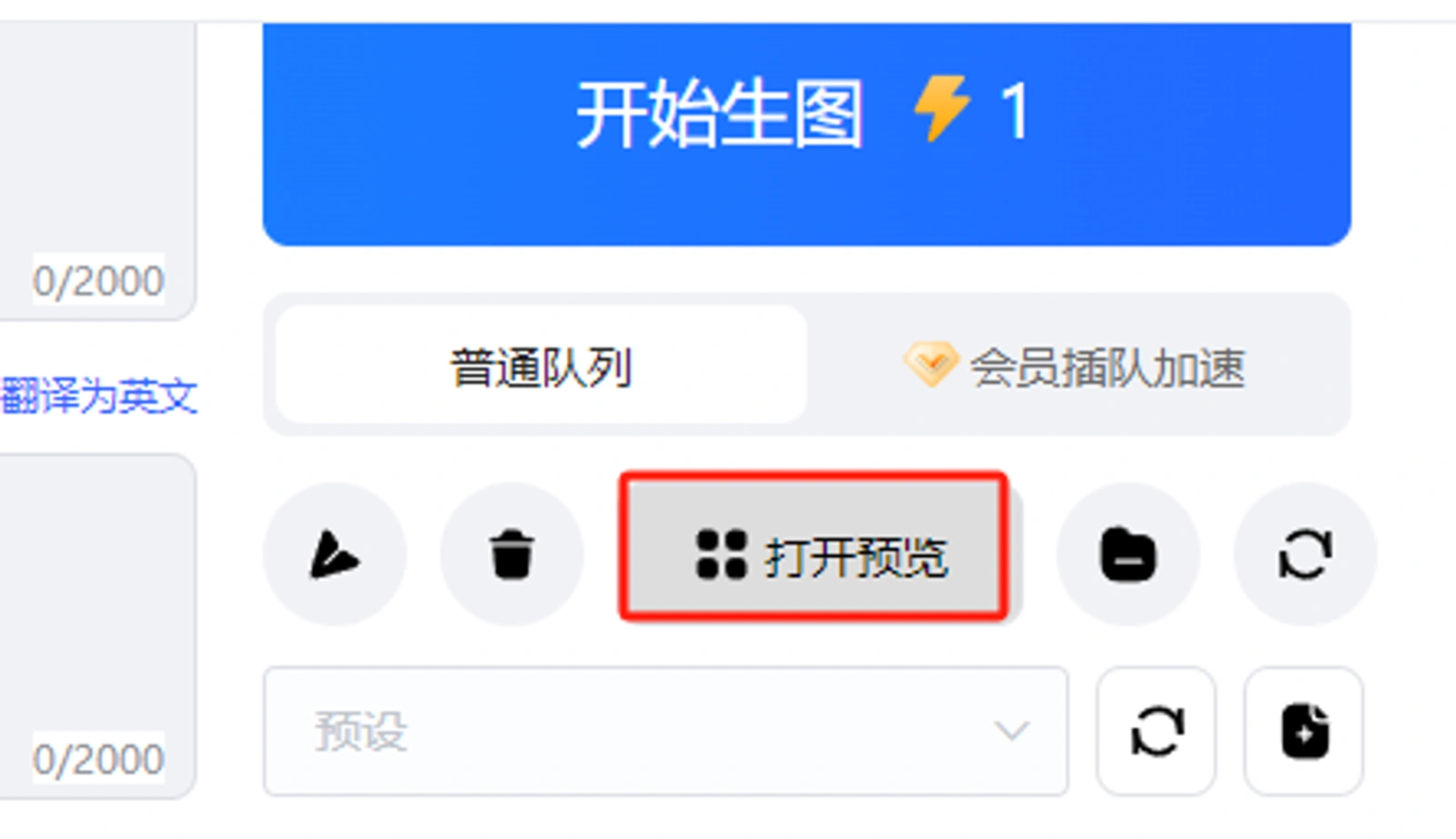
和收藏大模型一样,在模型广场上也一样可以查找添加Lora小到自己的模型库,打开对应模型页面后还可以查看模型创作者给你的玩法提示,帮助你设置你的参数。 在作图界面的提示词操作区点开【打开预览】(如下截图)可以看到自己收藏的Lora 模型。甚至于你也可以训练你自己的lora模型(本地部署才可以,在线版不行)。

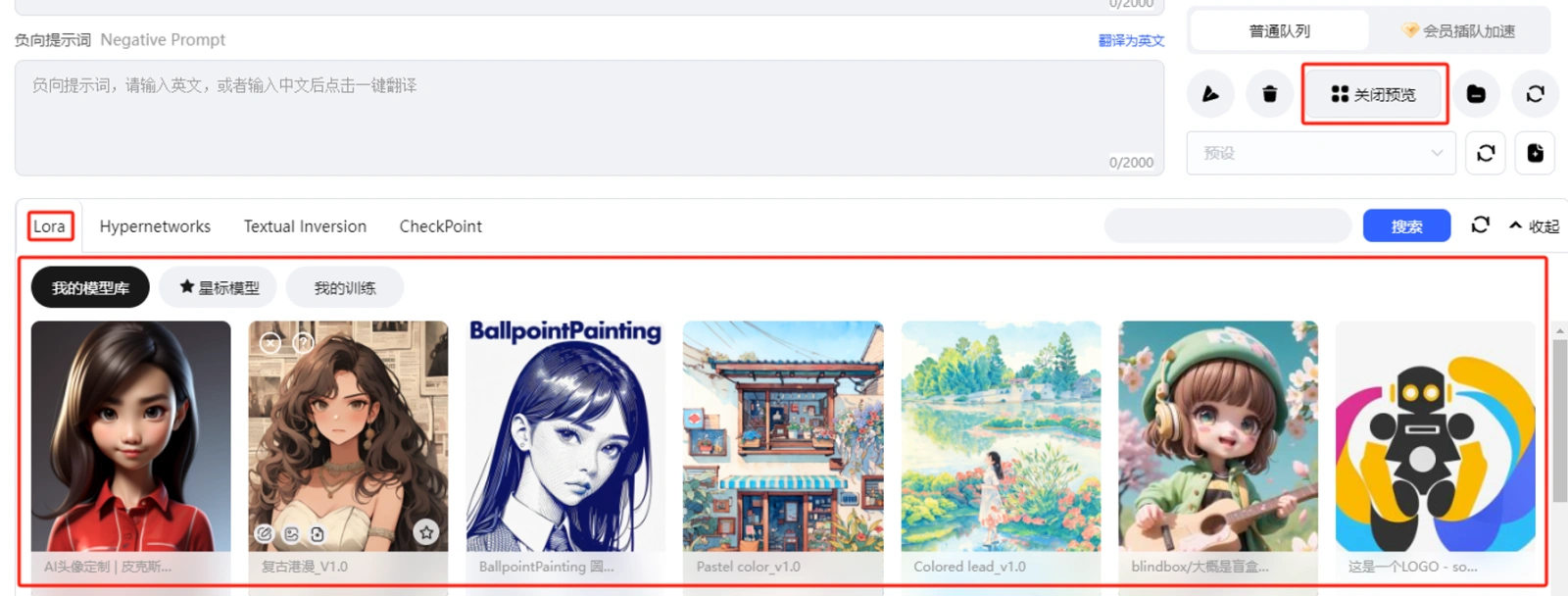
4.关于提示词
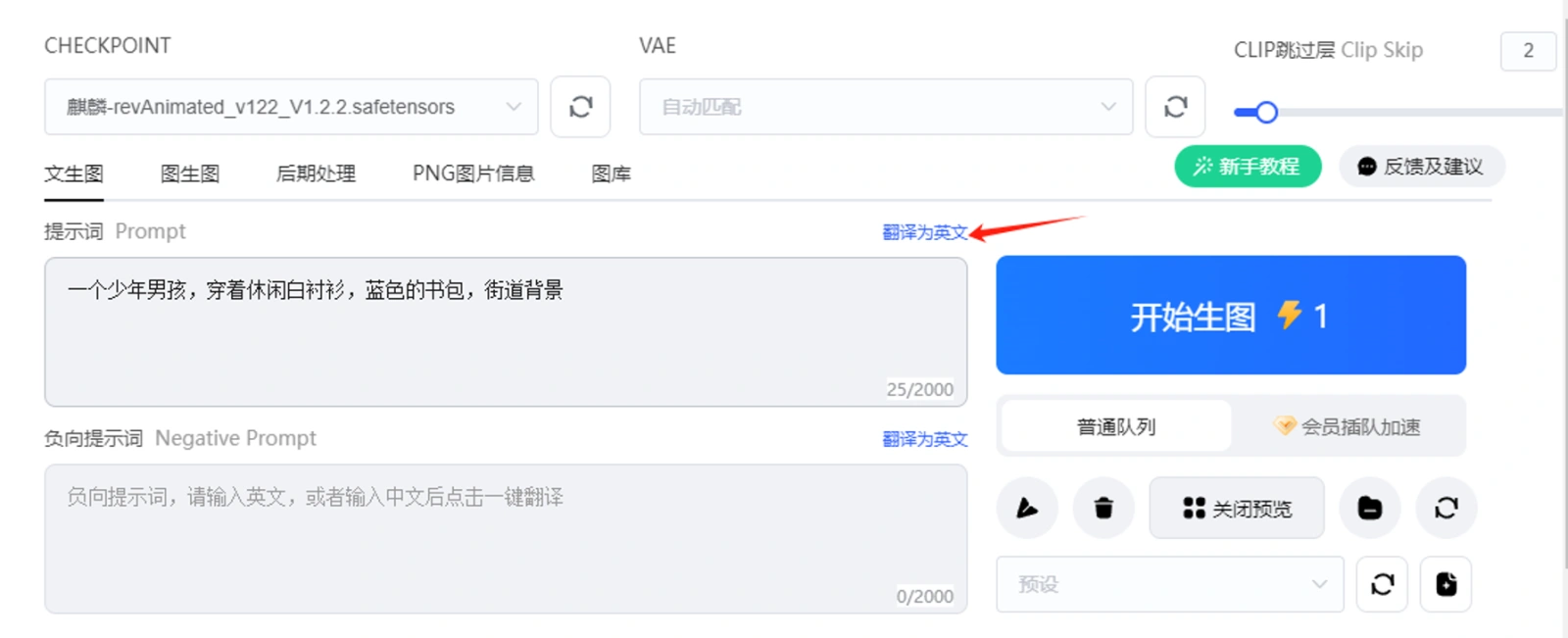
SD 里提示词区域包括正面提示词和负面提示词。负面提示词即你不想要画面中出现的内容,你也可以不填写。总体来说,如果你已经对MJ有所了解到话,提示词对你来说就很简单。并且在这里你直接用中文写也可以,然后点击右上角的翻译,它可以帮你翻译为英文。
注意:1.相比于MJ可以理解长句子,SD更适合短语。2.提示词中画风描述词要与所选择的大模型相匹配。如果有冲突,系统会优先按模型效果。比如你选择的模型是二次元的Awpainting,提示词写了写实风格,最后生成的图依然会是二次元风格。
💡 关于prompt的一些规则: 1.权重设置:(提示词)给提示词加一层小括号表示增加权重1.1倍,加2层小括号,((提示词))即增加权重1.1乘1.1=1.21倍;[提示词]给提示词加一层中括号表示降低权重为0.9倍,同理两层总括号即降低权重0.9乘0.9=0.81倍; (提示词:1.X)代表提升提示词权重1.X倍 ;(提示词:0.X)代表降低提示词权重0.X倍。这个方式设置权重更推荐。2.利用步数做渐变:提示词1:提示词2: 数字 如果数字<1,则表示前 (步数乘以数字) 步,以提示词1生成,之后按照提示词2生成;
如果数字>1,则表示,前(数字)步,以提示词1生成,剩下步数以提示词2生成。
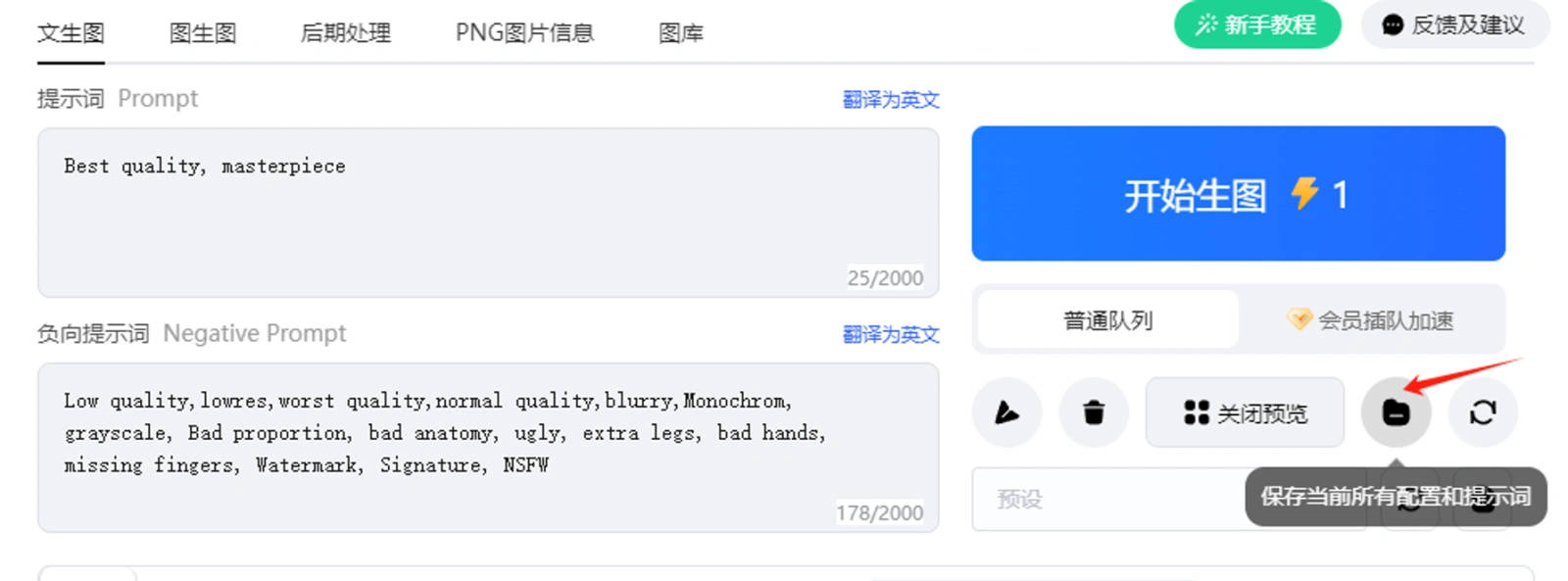
💡 Tips:可以将常用的正向和负向提示词提前预设:写进去,然后点击右侧提示词操作区的保存按钮,如下图,我在证明和负面提示词框内写上通用的高质量图片提示词,点击右侧【保存当前配置和提示词】,进行命名,后续点击下方的预设,就可以添加自己预设的内容。如果想修改,修改后,重复保存,会将原来保存的内容覆盖。 比如下图我预设保存了自己的固定提示词,取名为高清高质量写实照片。下一次我就可以直接右侧区域选择,提示词就可以自动添加进去。
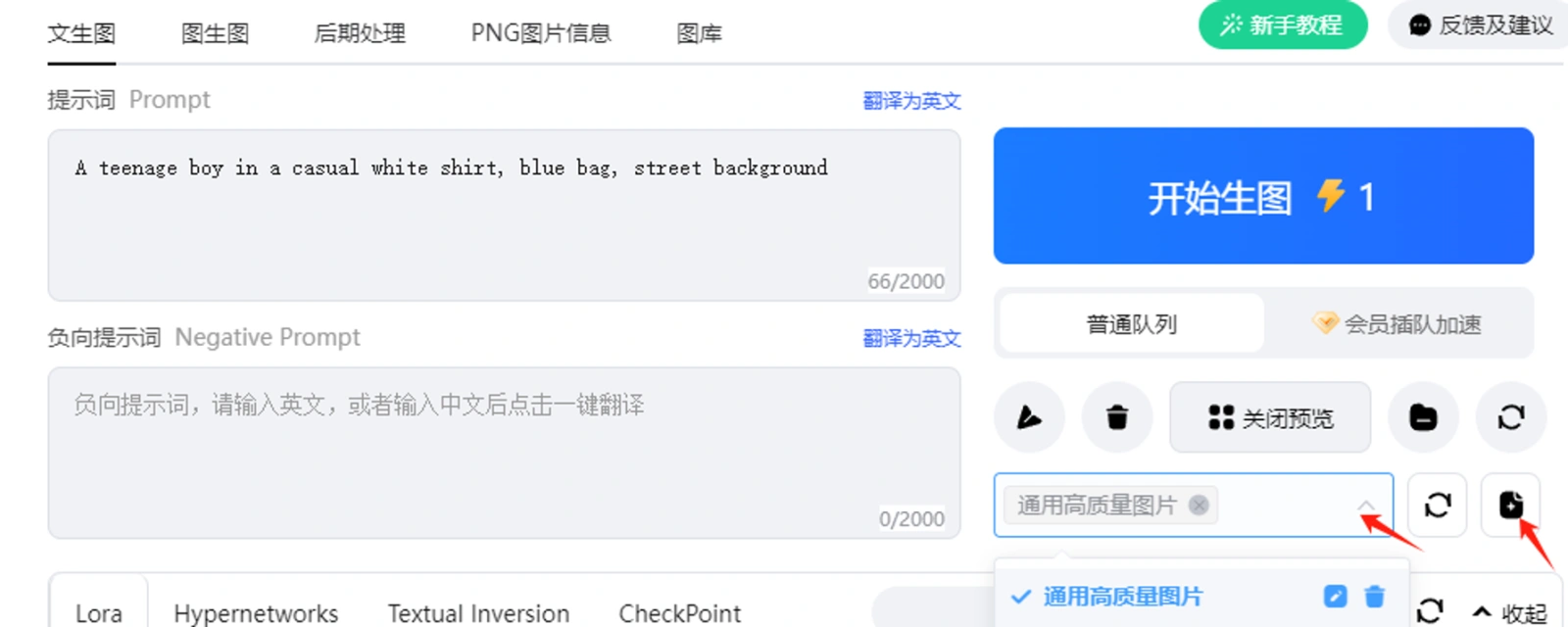
选择刚才保存的预设提示词,再点击右侧添加按钮,就可以看到预设的提示词加进了提示词框内。
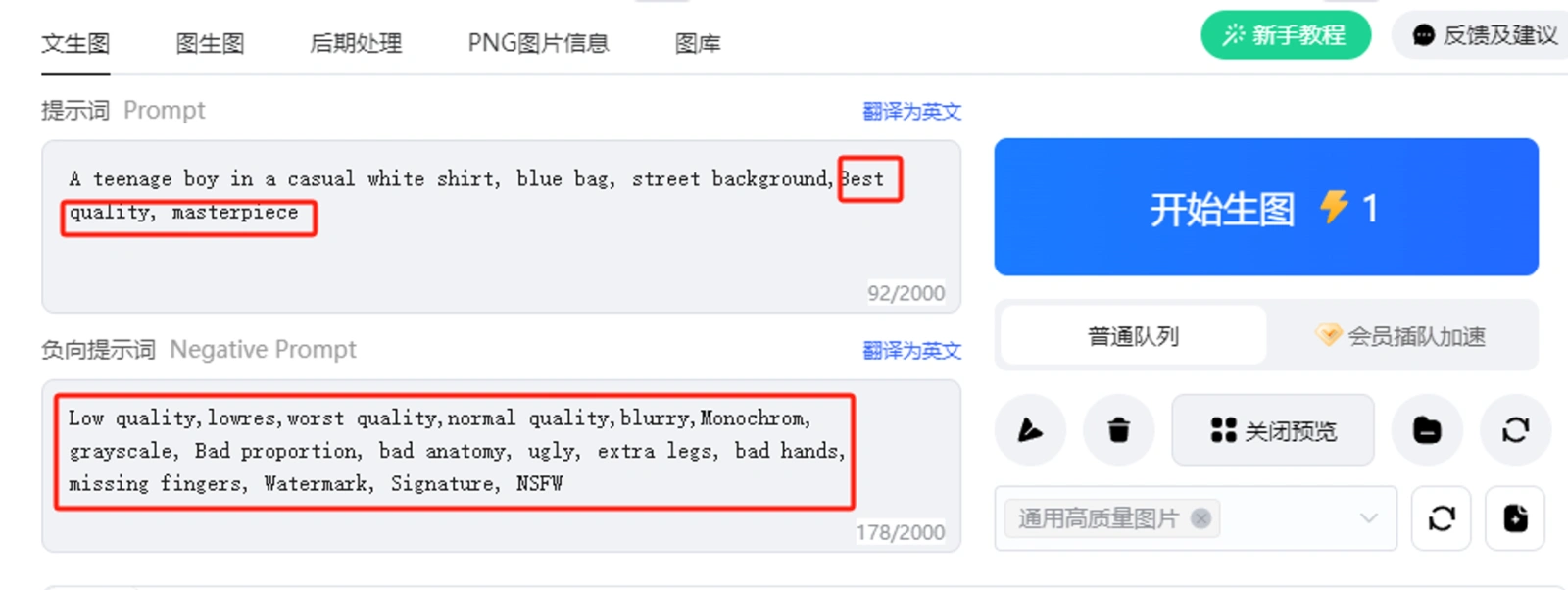
如果想要皮克斯风格,可以将刚才添加的皮克斯Lora模型选上,可以点击上面的小图标,将触发词加上。
5.认识基础参数
采样方法参数
它指的是不同的算法,代表了不同的生成图片的效率。速度方面 DDIM 最快,目前比较推荐和网上使用最广泛的几种为Euler a, DPM++ 2M karras, DPM++ SDE karras, DDIM,属于速度快且质量有保证。
注意:不同的采样方式可能对不同的模型产生不同的影响,因此采样方法的选择最好的方法就是多尝试。
迭代步数
指用多少次来计算你提示词里的内容。步数不是越高越好,15-30之间比较适合,最大不要超过50步,推荐值25步左右。
面部修复、平铺、高分辨率修复
面部修复:通常用于实景图出现面部崩坏的情况,开启此功能,面部崩坏的情况会有一定的改善,但不建议用于二次元的图。
平铺:用于出无缝衔接的重复性花纹,可以按瓷砖,壁纸效果来理解。
高分辨率修复与重绘幅度:高清修复即增加原有图像分辨率,同时也可以调整原图像。
勾选高清修复时,后出现重绘幅度选项。高分辨率修复的重绘幅度为0时不会改变原图,0.3 以下会基于原图稍微修正,超过 0.7 会对原图做出较大改变,1 会得到一个完全不同的图像。
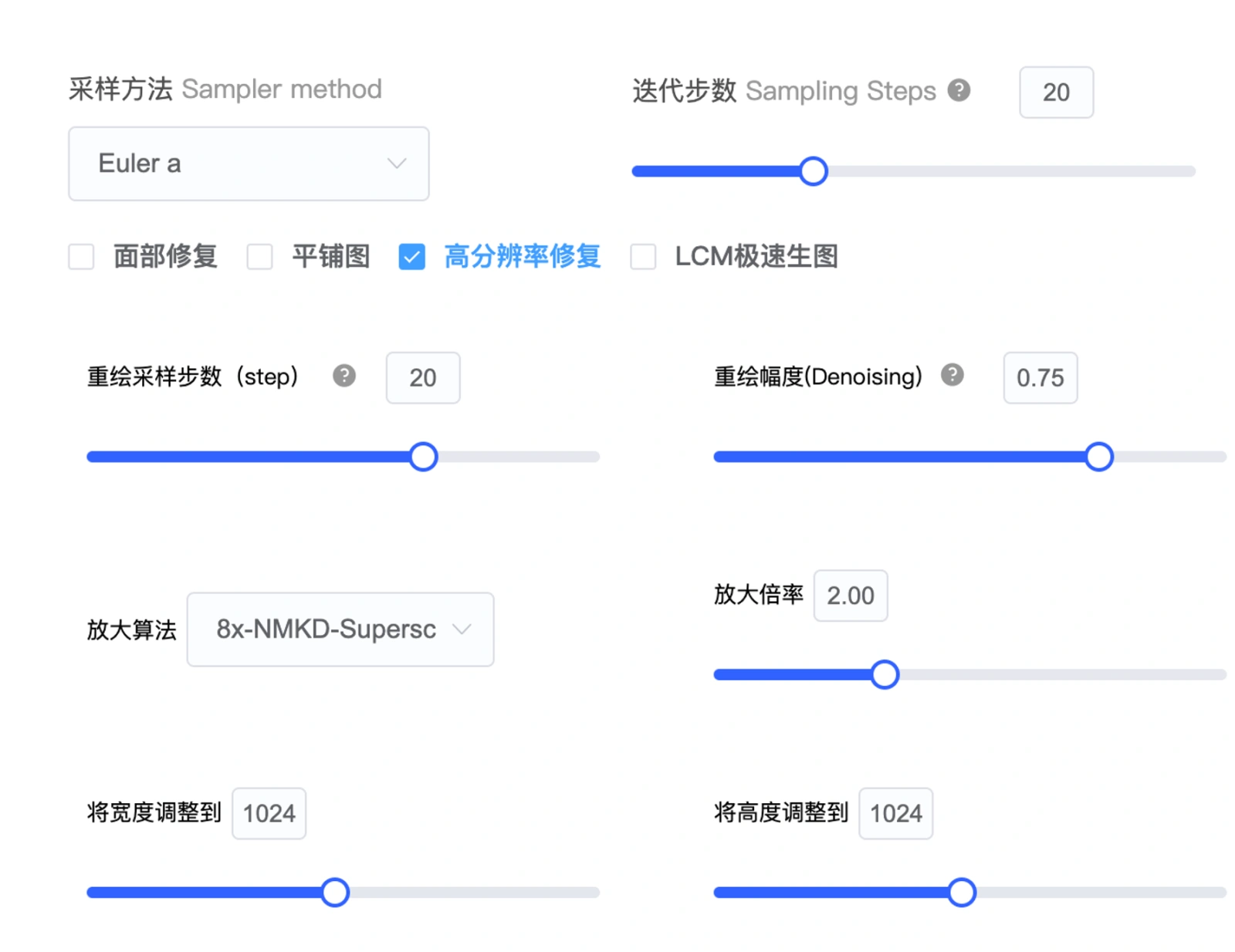
当面部崩坏需要修复时面部修复和高清修复二者选其一就好,两个都开可能适得其反。
宽度与高度
也即分辨率。最大为1024✖️1024如果你想生成更高清图像,建议生成小分辨率尺寸然后再用高清修复功能。
生图的批次与数量
这个很好理解,即每次生成多少组图,每组图多少张。一次性生成张数越多,响应时间会越长。
对于安装本地部署的小伙伴的建议: 中低显存 (6G、8G)的显卡,选择设置多批次,每批次生成1张图,降低对显卡的压力; 高显存 (12G、16G、24G)的显卡,可以设置单批次,一次性生成多张图。
提示词引导系数CFG
数值越高越接近提示词内容,默认0.7较为合适,过低的CFG,AI自由发挥的空间大,过高的CFG,会让画面过饱和,甚至出现瑕疵,(过大的CFG值,可以通过提高采样步数来抵消)。合适的CFG范围5-12之间,常用7或9搭配合适的送代步数15-30使用。
随机种子(类似MJ中的种子)
当随机种子为-1时,则是未使用种子,后续出图都是随机状态;每次通过SD生成的图片都会有一个随机种子seed值,可以填入随机种子参数位置,固定随机种子值后,后续生成的图片都会参考这个种子进行生成。点击随机种子区域右侧类似掉头的箭头图标,在随机种子框中即可快速填入当前图片的随机种子。
如果我们想要固定某个形象,可以尝试把图片的随机种子值填在Seed里,这样每次出图的风格大致都会一样。

Tips:可以利用高分辨率修复以及种子值,养成先用小图测试再选择高分辨率修复,固定种子生成高清图的好习惯
第一步:低分辨率快速抽卡(选择低分辨率512*512,总批次选4,每批次选1,可以快速出4张图)
第二步:在多次抽卡确认效果后,锁定满意效果的种子值,再选择高分辨率修复,可得到满意的高清图。
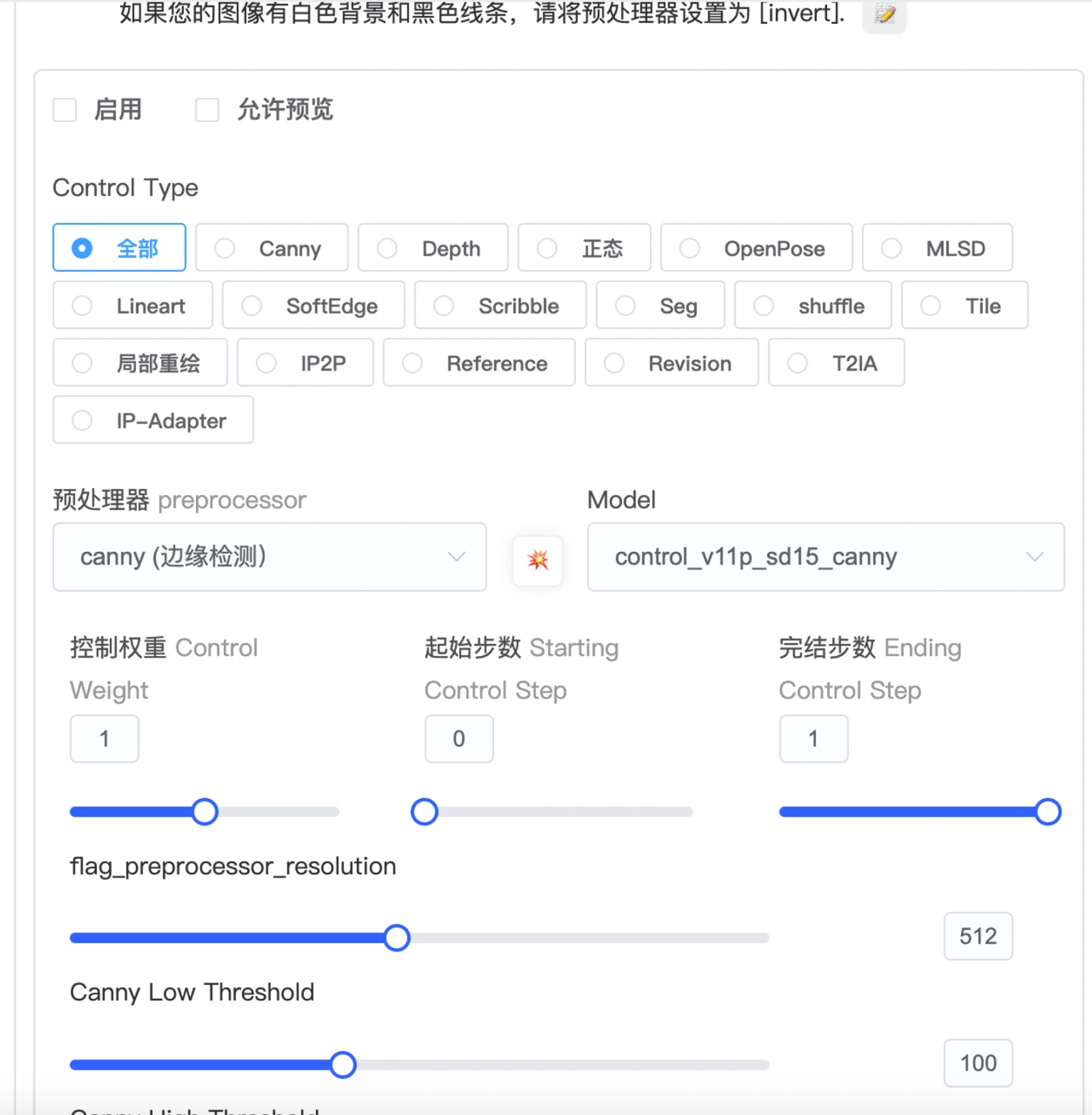
ControlNet功能
这个功能可以实现更加精准控制。选取不同的预处理器,可以提取你上传画面的构图,人物的姿势和画面的深度信息等等,让SD按照你给的图片参考信息来出图,来精准控制需要生成的图片。有了它的帮助,就不用频繁用提示词碰运气抽卡式创作了。这个是目前在AI绘图方面得到较高认可的功能。(展开后有其各种详细参数如下截图,此功能在基础篇不做详细介绍。)
三、根据提示词自己动手尝试吧
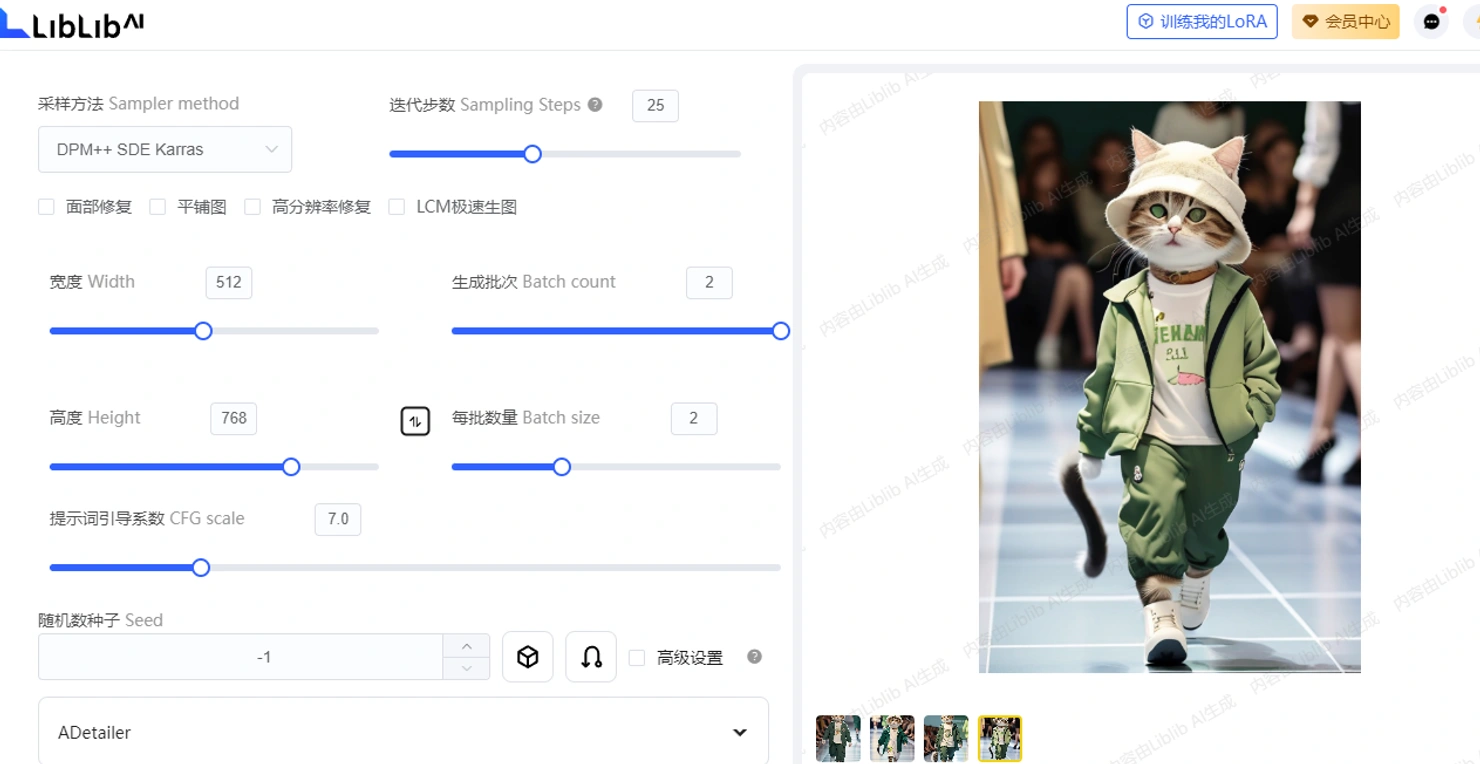
以下是一个提示词和参数的范例,自己动手操作吧,只有尝试,你才能明白每一个参数的功能和效果。
【猫猫模特主题】
- liblib上模型:realistic VisionV50_v50VAE.safetensors
- liblib上Lora:catman,权重0.7 (它的触发词是maomi,可以先去模型广场上搜索这个模型的介绍信息)
- VAE:自动匹配
- 采样算法:DPM++ SDE Karras
- 采样步数:25
- 宽度:512
- 高度:768
- 提示词引导系数:7.0
- 正向提示词:(Best quality, masterpiece: 1.2), cat, cute, anthropomorphic, on the runway, children's clothing, green, loose casual suit, Maine cat, maomi 翻译:(最佳质量,杰作:1.2),猫咪,可爱,拟人化,在T台上,童装,绿色,宽松休闲套装,缅因猫
- 负向提示词:(EasyNegative:1.2), badhandv4,ng_deepnegative_v1_75t,worst quality, low quality, monochrome
(以上提示词里相关颜色,服装的描述你都可以根据你的喜好调整)
下面这是我的参数页面截图,以及生成的图片,你的图是怎样的呢?